
Jak bardzo istotne dla codziennego funkcjonowania naszych klientów jest dostarczane przez nas oprogramowanie? Najczęściej przekonujemy się o tym wtedy, kiedy przestanie działać. W tym wpisie postaram się opowiedzieć o tym jak tego uniknąć.

Awarie systemów
7 sierpnia 2019 roku system informatyczny British Airways obsługujący londyńskie lotniska uległ awarii. W rezultacie ponad 500 lotów zostało odwołanych lub poważnie opóźnionych. Problemy “rozlały się” również na inne lotniska, gdzie nie dotarły samoloty, które nie mogły wylecieć z Londynu, wywołując efekt domina. Kilkadziesiąt tysięcy pasażerów odczuło na własnej skórze skutki awarii systemu, która trwała kilka godzin. Możecie sobie wyobrazić co działo się w firmie produkującej to oprogramowanie.
Inna historyjka, tym razem z własnego doświadczenia. Rano wypuściliśmy nową wersję naszego systemu. Wszystko idzie jak z płatka, nikt nie zgłosił żadnych poważnych błędów, w dodatku w tej wersji wypuściliśmy zmiany, które znacząco poprawiają wydajność i na monitoringu to widać. Jest godzina 17 i część ekipy poszła już do domu kiedy wszystko się zmienia. Monitoring zaczyna pokazywać spadek wydajności, a chwilę później już tylko płaska linia – system nie odpowiada. Zaczynamy reanimację, a klienci zaczynają dzwonić do supportu. Ciśnienie na uruchomienie systemu robi się olbrzymie. Nie będę wnikał w szczegóły tego, co poszło nie tak, powiem tylko, że stworzyliśmy wąskie gardło, które dało o sobie znać, kiedy zwiększył się ruch z USA. Diagnoza i naprawa zajęły dwie godziny. Najciekawsze było jednak to, czego się można było dowiedzieć z telefonów od naszych klientów. Jeden z nich, dyrektor z dużej agencji reklamowej, wyjaśnił nam, że w tej chwili 70 osób z jego zespołu, które pracują przy projektach z bardzo krótkimi deadline’ami, siedzi bezczynnie, bo nasz system jest im niezbędny do pracy. Do tamtej pory nie zdawałem sobie sprawy, że efekt mojej pracy jest tak ważny dla wielu osób.
Co mają ze sobą wspólnego te przykłady poza awarią w centrum wydarzeń? Oba pokazują jak krytyczne dla biznesu są dziś systemy informatyczne. Nawet kilkugodzinna niedostępność kluczowego systemu może mieć gigantyczne konsekwencje, czasem odczuwalne przez tysiące osób. Podobne obserwacje doprowadziły do zdefiniowania pojęcia systemów wysokiej dostępności (ang. high availability) i powstania dziedziny jaką jest inżynieria niezawodności (ang. reliability engineering).
Pięć dziewiątek
Wysoka dostępność oprogramowania (ang. high availability) mierzona jest zazwyczaj w dość nietypowej jednostce – “dziewiątkach”. Wynik rzędu trzech dziewiątek oznacza, że system jest dostępny średnio przez 99,9% czasu w danym okresie (najczęściej roku), cztery dziewiątki to 99,99% itd. Bardzo ambitnym celem, do którego wielu dąży jest pięć dziewiątek, co oznacza, że w skali roku system może być niedostępny przez co najwyżej 5 minut i 15 sekund. Inne popularne poziomy podsumowałem w tabelce poniżej:
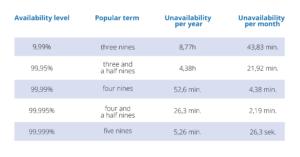
Podstawowe zasady
Zazwyczaj taka miara obejmuje jedynie nieplanowane przestoje systemu, natomiast planowane nie są brane pod uwagę w obliczeniach. Jeśli chcielibyśmy również je uwzględnić, mówimy o dostępności ciągłej (ang. continuous availability), której osiągnięcie jest jeszcze trudniejsze – ale nie o tym dziś będzie.
Praktyka pokazała, że chcąc tworzyć systemy o wysokiej dostępności nie można polegać na działaniach ad hoc, ale trzeba o niezawodność zadbać w sposób systemowy. Inżynieria niezawodności definiuje trzy podstawowe zasady, które pozwolą nam osiągnąć wysoką dostępność:
Eliminacja pojedynczych punktów awarii (ang. single point of failure, SPOF)
System powinien być tak skonstruowany, żeby awaria żadnego pojedynczego komponentu nie doprowadziła do awarii całego systemu.
Niezawodne przejście. W przypadku awarii komponentu, system powinien przejść w tryb pozwalający pracować bez tego komponentu. Praktyka pokazuje, że często sam mechanizm przełączania czy też monitorowania awarii może stać się pojedynczym punktem awarii.
Wykrywanie awarii kiedy się pojawią
Jeśli w systemie nie mamy pojedynczych punktów awarii i mamy niezawodny mechanizm przejścia, to może się zdarzyć, że wystąpi awaria, której nie zauważymy. Dlatego ważne jest, że o ile awaria pojedynczego komponentu systemu ma być niezauważalna dla użytkownika, to musi ona być doskonale widoczna dla operatora.
Bazując na własnym doświadczeniu, do powyższych punktów dorzuciłbym odporność systemu na błędy ludzkie. Historia zna niezliczone ilości przypadków, kiedy drobna pomyłka operatora doprowadziła do poważnej awarii systemu, nawet takiego, który był zaprojektowany z myślą o radzeniu sobie z awariami sprzętowymi i programowymi.
Tolerancja awarii (ang. fault tolerance)
To właściwość systemu objawiająca się tym, że może on kontynuować pracę w przypadku awarii jednego z komponentów. Wydajność i funkcjonalność systemu może być w takim przypadku niższa niż “zdrowego”, ale co najwyżej proporcjonalnie do wielkości awarii.
Najczęściej stosowanym narzędziem pozwalającymi osiągnąć odporność na awarie jest redundancja, czyli zapewnienie większej ilości komponentów danego rodzaju niż konieczna do normalnej pracy. Podczas normalnej, nieawaryjnej, pracy nadmiarowe komponenty mogą być nieobciążone (zapasowe) lub przejmować część obciążenia podstawowych komponentów (load balancing).
W rzeczywistym świecie zapewnienie tolerancji awarii wszystkich komponentów systemu może nie mieć praktycznego sensu, albo wręcz być niemożliwe. Dlatego podejmując decyzję które komponenty powinny być zdublowane możemy posłużyć się trzema kryteriami:
- Jak bardzo krytyczny jest komponent?
- Jakie jest prawdopodobieństwo awarii komponentu?
- Jaki jest koszt zapewnienia tolerancji awarii komponentu?
Jeśli dany komponent jest krytyczny dla działania systemu, prawdopodobieństwo jego awarii jest istotne, a koszty akceptowalne – powinniśmy zadbać o tolerancję awarii w tym miejscu.
Posłużmy się przykładem spoza branży IT. W dużych samolotach za poruszanie powierzchniami sterowymi zgodnie z intencją pilota odpowiedzialny jest system hydrauliczny. Jego działanie jest krytyczne w czasie lotu, awaria może doprowadzić do katastrofy – pierwsze kryterium spełnione. Prawdopodobieństwo rozszczelnienia się układu i wycieku płynu jest istotne – historia pokazuje, że takie przypadki się zdarzają – to drugie kryterium. Koszt zapewnienia tolerancji awarii, w tym przypadku poprzez zdublowanie systemu hydraulicznego jest akceptowalny – tu możemy uwzględnić zarówno koszt finansowy (niewielki w porównaniu z ceną samolotu) jak i niefinansowy – na przykład zwiększoną masę samolotu. Spełniamy więc też trzecie kryterium. Jak się okazuje, rzeczywiście, współczesne samoloty są wyposażone w podwójny, a często potrójny układ hydrauliczny.
Nadzieja to nie strategia
Wysoka dostępność systemu, zwłaszcza rzędu czterech dziewiątek i wyżej, nie jest łatwa do osiągnięcia. Zastanówmy się jak w najbardziej klasycznym przypadku wygląda reakcja w przypadku awarii. Ktoś (często, o zgrozo, klient) zauważa, że system nie działa. Informacja trafia do osób odpowiedzialnych za jego utrzymanie – najczęściej administratorów. Osoby te sprawdzają co się stało w systemie i naprawiają uszkodzony komponent, często wzywając po drodze innych potrzebnych specjalistów. Nawet jeśli zrobią to naprawdę sprawnie, cała operacja zajmie zazwyczaj przynajmniej długie minuty, jeśli nie godziny. Jeśli naszym celem jest mniej niż godzina niedostępności rocznie, to nie możemy sobie na to pozwolić.
Benjamin Treynor Sloss z Google wprowadził termin Inżynierii Niezawodności Lokacji (ang. Site Reliability Engineering), żeby opisać co by się stało, gdyby utrzymanie pracującego systemu zamiast administratorom powierzyć programistom. Jest to w pewnym sensie analogiczna koncepcja do testów automatycznych, gdzie zamiast manualnie testować wielokrotnie ten sam scenariusz automatyzujemy go. W ten sam sposób, jeśli chcemy stworzyć niezawodny system powinniśmy maksymalnie zautomatyzować reakcje na awarie, które mogą się w nim pojawić. Mówimy tu zarówno o obserwowaniu systemu w celu wykrycia awarii (monitoring, telemetria), automatycznym powiadamianiu odpowiednich osób (on-call) jak też – przede wszystkim – automatycznym rozwiązywaniu problemów.
Wysoka dostępność systemu jest coraz częściej kluczowym niefunkcjonalnym wymaganiem stawianym przed jego twórcami. Osiągnięcie satysfakcjonującego dla klientów poziomu niezawodności nie jest zadaniem trywialnym. Musimy projektować nasz system w taki sposób, żeby był niewrażliwy na awarie pojedynczych komponentów, pozwalał na łatwe wykrywanie awarii i w sposób zautomatyzowany radził sobie z nimi.
Zobacz też: Cyfrowa transformacja to „must have” każdego biznesu

