
How crucial is the software we provide in the daily operations of our customers? Most often we only learn that when it stops working. In this post I delve into the ways in which we can avoid such situations.

System malfunctions
On August 7, 2019, British Airways’ IT system for London airports went down. Consequently, over 500 flights were cancelled or severely delayed. The problems spilled into other airports as well since planes scheduled to land there couldn’t leave London in the first place, which resulted in a significant domino effect. Several tens of thousands of passengers experienced for themselves the effects of a system malfunction which lasted for a couple of hours. You can only imagine the havoc it all wreaked in the company which had manufactured the software.
Another story, this time from my own experience. In the morning we release a new version of our system. Everything is going smoothly, nobody is reporting any serious error. What’s more, in this version significantly improved the performance, which is confirmed by what we can see on our monitoring system. It’s 5 p.m., a part of the team has already gone home when things suddenly begin to change. The monitoring reports a drop in performance, and a moment later it’s flatlined – the system stops responding.
We try to bring it back to life while clients begin to call our support. The pressure to get the system up and running becomes enormous. I won’t go into detail of what actually had gone wrong that fateful afternoon, but let me just say that we ended up creating a bottleneck which became apparent only once the traffic from USA increased.
A proper diagnosis and fixing the problem took two hours. What was the most interesting, though, were the things we learned from our clients’ phone calls. One of them (clients, not phone calls), a director in a large advertising agency explained to us that at that particular moment 70 people of his team, who typically work with very short deadlines, had been sitting idly since our system was essential for their work. Until that moment I had not realized the impact of my work on so many people.
So what do these cases have in common, other than a system failure as the main event? Both show how critical for business today’s IT systems actually are. Even a mere couple of hours of a key system’s unavailability may have enormous consequences, sometimes experienced by thousands of people. Similar observations have led to a definition of a high availability system term, and to the creation of the reliability engineering domain.
Five nines
Software system’s high availability is typically measured in a somewhat unusual unit – “nines.” A result of three nines means that a system is available on average for 99.9% of time in a given period (usually a year), four nines being 99.99% of time, and so on. A very ambitious goal, sought by many, is to achieve the result of five nines, which would mean that on a yearly basis a system may be unavailable for the maximum of 5 minutes and 15 seconds.
I have summarized other popular levels in the chart below:
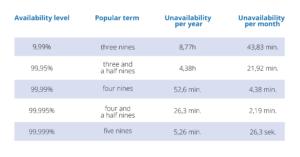
Usually, such a measure includes only unplanned system hold-ups, with the planned ones not being taken into account in the calculations. If we wanted to include the planned hold-ups as well, we would be talking about continuous availability which is way harder to achieve. But that’s not our main focus today.
Basic principles
Practice shows that while creating high availability systems one should not rely on ad hoc activities, but rather ensure reliability in a systemic manner. Reliability engineering defines three basic principles which enable us to achieve high availability:
Elimination of single points of failure (SPOF).
The system needs to be constructed in such a way that a failure of any single component does not lead to the failure of the entire system.
Reliable transition. In case of a component’s failure, the system should make a transition into a mode which enables operation without that particular component. Practice shows that often the switching or monitoring mechanism itself can become a single point of failure.
Detecting failures as they happen. If our system does not have any single points of failure, and we have a reliable transition mechanism, it may happen that a failure will appear and we won’t even notice it. That’s why a failure of a single component must be visible to the operator as much as it should not be noticeable to the user.
Basing on my own experience, I would add to the above system’s resistance to human errors. History knows countless cases when a minor mistake by the operator led to a major system malfunction, including the systems which were designed specifically to deal with hardware and software failures.
Fault tolerance
Fault tolerance is a system’s property which consists in the system being able to continue operating in case of one of its components’ failure. Efficiency and functionality of a system may in such a case be lower than that of a “healthy” system, but proportional to the size of the failure at most.
The most commonly used tool which enables to achieve fault resistance is redundancy, which means providing a number of components of a given kind which is higher than required in case of normal work. During normal, fault-free operation, surplus components may be unloaded (spare) or may take over a part of the load from primary components (load balancing).
In a real world, ensuring fault tolerance of all system’s components may have little practical sense, or be completely impossible. That’s why when making a decision about which components to double, we can incorporate three criteria:
- How critical is the component?
- What is the likelihood of the component’s failure?
- What is the cost of ensuring fault tolerance of the component?
If a given component is critical for the system’s operation, the likelihood of its failure is high, and the costs are acceptable – that’s where we should ensure fault tolerance.
Let us use an example from outside the IT industry. In large aircrafts, a hydraulic system is responsible for moving the control surfaces according to the pilot’s intentions. Its operation is critical during the flight, and a failure can lead to disaster – the first criterion is hence met. The probability of unsealing of the system and fluid leakage is important – history shows that such cases happen – that’s criterion number two. The cost of ensuring fault tolerance, in this case by doubling the hydraulic system, is acceptable – here we can take into account both the financial cost (minor, compared to the price of the aircraft) and the non-financial cost – for instance the increased weight of the aircraft. We therefore meet criterion number three as well. As it turns out, in fact, modern aircraft are equipped with a double, and often triple, hydraulic system.
Hope is not a strategy
High availability of the system, especially in the range of four nines and above, is not easy to achieve. Let’s consider what the reaction in case of a failure looks like in the most typical case. Someone (alas, often the customer) notices that the system is not working. The information goes to those responsible for its maintenance – most often administrators. They check what happened in the system and fix the broken component, often calling for other necessary specialists along the way. Even if they do it really efficiently, the whole operation will usually take at least long minutes, if not hours. Assuming our goal is to achieve less than an hour of unavailability per year, we can’t afford it.
Google’s Benjamin Treynor Sloss introduced the Site Reliability Engineering term to describe what would happen if the maintenance of a working system were entrusted to programmers instead of administrators . In a way, it is an analogous concept to automatic testing, where instead of manually testing the same scenario many times, we automate it. Similarly, if we attempt to create a reliable system, we should maximally automate the reactions to failures that may occur in it. We are talking about both observing the system to detect failures (monitoring, telemetry), automatic notification of the appropriate people (on-call) and – above all – automatic problem solving.
Summary
High availability of the system is increasingly becoming a key non-functional requirement its creators must face. Achieving a satisfactory level of reliability for customers is not a trivial task. We must design our system in such a way that it is insensitive to failures of individual components, allows for easy detection of failures and deals with them in an automated way.
Andrzej Zoła, Delivery Manager
